
Optimizing MongoDB Aggregation
Thu 01 February 2018ဘာမှမလုပ်လည်း အကုသိုလ်နဲ့ Error ဆိုတာက ဝင်ချင်တဲ့အချိန်ဝင်တာပဲ ဘယ်သူမှမထိထားတဲ့ Production သုံးနေတဲ့ API Servers တွေဟာ တနေ့နေ့လည်ကစပြီး Status 400 တွေ အများကြီးတက်လာလိုက် ပြန်ကောင်းသွားလိုက်နဲ့ ဖုတ်လိုက်ဖုတ်လိုက် ဖြစ်နေပါရော။ Clients တွေကလည်း ကောင်းနေရင် ဖုတ်လေတဲ့ငပိလို သဘောထားပေမယ့် Server တခုခုဖြစ်ရင်တော့ ဖုန်းတွေဆက်လိုက်ကြတာ ဘာပြောကောင်းမလဲလေ။
API Lists တွေကို တခုချင်းစစ်ကြည့်ကြတယ် ရုံးသာဆင်းသွားတယ် ဘယ်လိုမှလည်း အဖြေကရေရေရာရာ မထွက်လာပါဘူး။ မိုးလင်းသွားမှ MongoDB Server တလုံးမှာ Deadlock ဖြစ်ပြီးတော့ Server က ဘယ်လိုမှမရှင်းနိုင်ပဲနဲ့ တခါတခါမှာ Hang နေတာကနေ သဲလွန်စအနေနဲ့ စပြီးတွေ့တယ်။ Lock ဖြစ်နေတဲ့ Collection ကို လာဖတ်လာရေးတဲ့ command ပါတဲ့ API ဝင်လာတာနဲ့ နောက်လူတွေအကုန် Timeout တွေဖြစ်ပြီး ရပ်ကုန်လိုက်နဲ့ မုန့်လုံးစက္ကူကပ်တာပဲ။ Operations တွေကို Force နဲ့ ရှင်းထုတ်လိုက်ပြီး Service ကို Restart လုပ်လိုက်တော့မှပဲ ပြန်အလုပ်လုပ်သွားတယ်။
နည်းနည်းလောက် အသက်ရှူချောင်သွားပေမယ့် Deadlock ဖြစ်ရခြင်း အကြောင်းအရင်းကို ရှာရဦးမှာဖြစ်တော့ ပြဿနာဖြစ်သွားတဲ့ MongoDB Server ရဲ့ Logs file ကို ဆွဲယူပြီးတော့ သဲလွန်စရှာရတော့တယ်။ MongoDB မှာတခု Profiling က Default အနေနဲ့ Slow Query တွေကို Log မှာ မှတ်ထားပေးတော့ နည်းနည်းတော့ အသက်ရှူချောင်သွားတယ် မဟုတ်ရင်တော့ သဲလွန်စကို ဘယ်ရှာရမှန်း သိမှာမဟုတ်တော့ဘူး။ ဒါပေမယ့် ကိုယ့်ရဲ့ API တွေမှာက Analytic Dashboard တွေအတွက် ပေါက်ပေါက်ရှာရှာ Summarize လုပ်ထားတွေက အင်မတန်နှေးမှန်းသိတယ် ရေးတဲ့လူတွေကလည်း သူတို့တတ်နိုင်သလောက် လုပ်ထားကြတယ် မနိုင်တော့ဘူးဆိုပြီး စစ်ကူတောင်းထားပေမယ့် ကိုယ်မအားတာနဲ့ အဲဒီဘက်ကို မလှည့်နိုင်တာ။
မျှော်လင့်ထားတဲ့အတိုင်းပဲ Logs တွေက အားလုံးပေါင်းရင် GB နဲ့ချီပြီးရှိတဲ့အတွက် နည်းတာမဟုတ်ဘူး ဘယ်လိုမှ Manually ကြည့်လို့မဖြစ်နိုင်တော့ Logs တွေကို Analyze လုပ်ဖို့အတွက် Tools လိုက်ရှာရင်းနဲ့ MongoDB ရဲ့ Blog ကနေတဆင့် mtools ဆိုတာကိုတွေ့တယ်။
Install mtools
$ pip install mtools
$ pip install matplotlib
Python နဲ့ ရေးထားတာတွေက Package Version အမျိုးမျိုးနဲ့ အင်မတန်လည်း ဖွတတ်တော့ virtual environments နဲ့ပဲ Install လုပ်တာပါ။ တခုတော့သတိထားပါ mtools ဟာ Python 2.7 မှာပဲ Support လုပ်ပါတယ်။ သူ့ရဲ့ Manual အတိုင်း pip နဲ့ Install လုပ်လိုက်ပေမယ့် mplotqueries နဲ့ Visualize လုပ်မယ်ဆိုပြီးစပြီး စမ်းလိုက်တော့ Error စတက်ပါတယ်။
mplotqueries
$ mplotqueries mongod.log
RuntimeError: Python is not installed as a framework. The Mac OS X backend will not be able to function correctly if Python is not installed as a framework. See the Python documentation for more information on installing Python as a framework on Mac OS X. Please either reinstall Python as a framework, or try one of the other backends. If you are using (Ana)Conda please install python.app and replace the use of 'python' with 'pythonw'. See 'Working with Matplotlib on OSX' in the Matplotlib FAQ for more information.
ရှာလိုက်ဖွေလိုက်တော့ Mac မှာဆိုရင် Tk သုံးဖို့အတွက်ထပ်ပြီးတော့ Config လုပ်ပေးရတယ်ဆိုလို့ အောက်မှာပြထားသလို ~/.matplotlib/matplotlibrc ထဲမှာ backend: TkAgg လို့ သွားရေးပေးလိုက်မှပဲ Visualize လုပ်လို့ရသွားတယ်။
$ echo "backend: TkAgg" > ~/.matplotlib/matplotlibrc
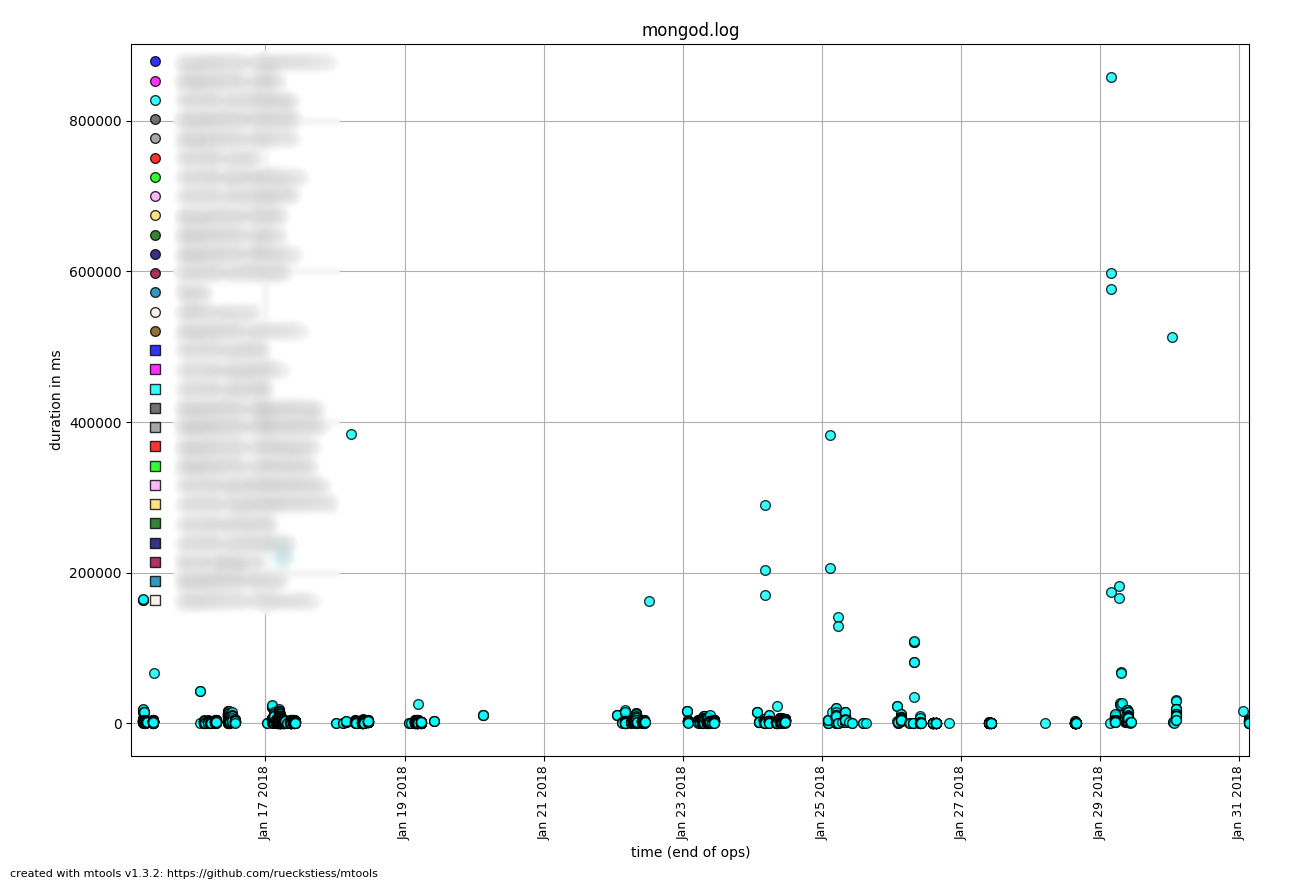
mplotqueries ရဲ့ Visualization ဟာ အတော်အသုံးဝင်တယ် ကြည့်လိုက်တာနဲ့ အချိန်အကြာဆုံး Query လုပ်တာခံရတဲ့ Collection ဟာ စက္ကန့် ၈၀၀ လောက် ကြာတယ်ဆိုတော့ ဘုရားတယူရတယ်။ အချိန်ကလည်း ပြဿနာစတက်တဲ့ အချိန်လောက်ဆိုတော့ ပြဿနာစတာ အဲဒီ Query ကနေစတာပဲ ဖြစ်ရမယ်လို့ ကနဦးအနေနဲ့ ခန့်မှန်းလို့ရတယ်။ Visualized လုပ်ပေးထားတာက Interactive ပါ ပုံမှန်အလုပ်လုပ်နေတဲ့ Collections တွေကို ပယ်လိုက်ပြီး ပြဿနာလုပ်နေတဲ့ Collection ရဲ့ Visualize လုပ်ထားတဲ့ Query တွေကို တခုချင်းကို Click လုပ်ကြည့်တော့ Query တွေကလည်း တခုနဲ့တခုမတူဘူး။ အများအားဖြင့်ကတော့ ထင်ထားတဲ့ အတိုင်းပါပဲ Aggregation လုပ်ထားတာတွေပါ။ Sample အတွက်က Click နှိပ်ကြည့်လို့ရပေမယ့် ဘယ်ဟာတွေပြင်ရမလဲ အကုန်သိရမယ်ဆိုတော့ mloginfo နဲ့ tools တခု ထပ်ပြောင်းရတယ်။
mloginfo
$ mloginfo mongod.log --queries
mloginfo ကလည်း အတော်အသုံးဝင်တယ် --queries နဲ့ထုတ်လိုက်တော့ Query တွေပဲ Filter လုပ်ပေးသလို Query တခုချင်းအလိုက် Count, Min, Max, Avg စသည်ဖြင့် ကြာချိန်ကို တွက်ပေးထားတော့ အတော်အဆင်ပြေတယ်။ အဲဒါတွေအပြင် 95%-tile ကိုပြထားပေးတော့ Max ဖြစ်နေတဲ့ တန်ဖိုးဟာ Outlier ဖြစ်နေမနေ သိလို့လွယ်တယ် တချို့ Query တွေဟာ အကြိမ်အများကြီးမှာမှ တခါလောက်ဖြစ်နေတာမျိုးကို အလွယ်တကူသိလို့ရတယ်။
mloginfo ကအသုံးဝင်ပေမယ့် မျက်လုံးပြူးရတာက ပြထားတဲ့ Query တွေထဲမှာ စက္ကန့် ၈၀၀ နဲ့ Query မပါလာဘူး သူ့အထဲက အကြာဆုံးဆိုတာတွေက ၇-၈ စက္ကန့်တွေဆိုတော့ မျက်စေ့မှိတ်ထားချင်ရင် မှိတ်ထားလို့ရတယ် ပိုပြီးတော့လည်း ကောင်းအောင်က လုပ်ချင်မှလည်းလုပ်လို့ရမှာပါ။ မဟုတ်သေးဘူးဆိုပြီး စက္ကန့် ၈၀၀ နဲ့ Query ကို Logs ထဲမှာ grep နဲ့ ရှာတော့လည်းတွေ့တယ်။ နောက်ဆုံးတော့ ပြဿနာက mloginfo က Aggregation တွေဆိုရင် Result မှာထုတ်မပေးဘူး။ mloginfo ရဲ့ Implementation ထဲမှာ အလွယ်တကူများ ပြင်လို့ရမလားလို့ ပြင်ကြည့်သေးတယ် Aggregation Query Line အတွက် Parse လုပ်တာ ပြန်ရေးပေးမှ ရမှာဖြစ်နေလို့ အချိန်မရှိတော့ ကိုယ့်နည်းကိုယ့်ဟန်ပဲ grap နဲ့ aggregate ဆိုတဲ့ စကားလုံးပါတဲ့ Line ကို ဆွဲထုတ်ရင် ရတာပဲဆိုပြီး ကြံရဖန်ရတယ်။
Aggregation Commands
$ grep aggregate mongod.log > aggregate_queries.log
ကြာနေတဲ့ Aggregation တွေကိုကြည့်တော့ ပိုပြီးခေါင်းခြောက်ရတာက ရေးထားတာတွေက ဖြစ်သလိုရေးထားလို့ ကြာနေတာတွေတော့ မဟုတ်ဘူးပဲပြောရမယ်။ Execution plan တွေမှာလည်း သာမန်ဖြစ်လေ့ရှိသလို Programmer က နားမလည်လို့ Index တွေမရှိလို့ Collection တခုလုံးကို Scan လုပ်နေတာမျိုးလည်း မဟုတ်ပြန်ဘူးဘူး ကိုယ့်လူတွေကလည်း သူ့နည်းသူဟန်နဲ့ မြန်အောင်ဆိုပြီး Index တွေက Hit မဖြစ်ဖြစ်အောင် Create လုပ်ထားကြတယ် အလုပ်လွန်ပြီး ပိုနေတာတွေရှိပေမယ့် သိပ်ကြီးတဲ့ပြဿနာလည်း မဟုတ်ဘူးပြန်ဘူး။ ဒါပေမယ့် အားလုံးမှာတော့ Lock ယူဖို့အတွက် စောင့်တဲ့အချိန်တွေတော့ ကြာနေတာအမြဲရှိတယ်။
အသေအချာဖတ်ရင်းနဲ့ Aggregation ရဲ့ Pipeline မှာပါတဲ့ Order တွေကို သံသယဝင်လာလို့ Documents တွေကို လိုက်ဖတ်တော့မှ MongoDB ရဲ့ Query Optimization ဟာ ရေးချင်သလိုရေး Optimized Plan ထုပ်ပေးနိုင်လောက်အောင် သိပ်မကောင်းမှန်းသိရတယ်။ သာမန်အမှားတွေဖြစ်တဲ့ Filter လုပ်ချတဲ့ match တွေလောက်သာ အနောက်မှာရေးထားရင် အရှေ့ပြန်ပို့တာတို့ပဲ လုပ်ပေးနိုင်တာတွေ့တယ်။ Query တွေကို အသေအချာသတိထားပြီး ပြန်ဖတ်ကြည့်တော့ Filter လုပ်ပြီးတာနဲ့ Sorting တွေလုပ်ထားကြတယ်။ အဲဒီထက်ပိုဆိုးတာက Sorting သာလုပ်တာ Sorted လုပ်ထားတဲ့ Field ကို ပြန်သုံးထားတာလည်း ဘယ်မှမှမရှိတော့ Sorting လုပ်တဲ့ အဆင့်တွေက အဆစ်ထည့်ထားတာ ဖြစ်နေတယ်။
သာမန်အနေအထားမှာ မသိသာပေမယ့် အဲဒီ Collection ထဲမှာက Documents တွေက ၉-၁၀ သန်းလောက်ရှိတာ ဘယ်လိုပဲ Filter လုပ်လုပ် အနည်းဆုံးက Documents သိန်းဂဏန်းနဲ့ ထွက်လာတယ်။ အဲလောက်အများကြီးကို ဘယ် Calculation တွေမလုပ်ခင် အဆစ်အနေနဲ့ Sorting စီတယ်ဆိုတော့ ဘယ်လောက်ပဲ Index Seek ဖြစ်ပြီးတော့ အမြန်ထွက်လာလာ သူမှမကြာရင် ဘယ် Process ကြာပါတော့မလဲ။ ပိုဆိုးတာက Aggregation က သတ်မှတ်ထားတဲ့ Memory ထက် ပိုသုံးလို့မရတော့ Disk Cache ကို သုံးတဲ့အတွက် ပိုပြီးတော့ကြာပါတယ်။ ကြာတဲ့အချိန်မှာ တချို့ Read Lock တွေ အကြာကြီးယူထားမိတာနဲ့ ရေးဖို့အတွက် စောင့်နေတဲ့ Process တွေနဲ့ ငြိကြဖို့များတယ်။ Query Plan တွေမှာ timeAcquiringMicros တန်ဖိုးကလည်း များတာတွေ့တော့ ခန့်မှန်းတာနဲ့ ကိုက်တယ်လို့ပြောရမယ်။
အကြာဆုံးဖြစ်တဲ့ Query တခုကိုဆွဲထုတ် အစမ်းအနေနဲ့ Execute လုပ်ကြည့်တော့ ကိုယ့်စက်ထဲမှာတော့ စက္ကန့် ၂၀ လောက်ကြတယ်။ ဟုတ်ပြီဆိုပြီးတော့ Pipeline ထဲက အဆင့်တွေကိုကြည့်တယ် တဆင့်ချင်းစီ Number of Documents အရပဲဖြစ်ဖြစ် Documents ထဲမှာပါတဲ့ Contents ပမာဏပဲဖြစ်ဖြစ် Data ပမာဏကို နည်းနည်းသွားအောင် သတိထားပြောင်းလိုက်တယ် အဆစ်ထည့်ထားတာတွေ ဖြုတ်လိုက်ပြီးတော့ လိုအပ်ရင်လည်း Sorting လို Cost ကြီးတဲ့ Operation တွေကို Data ပမာဏ အနည်းဆုံးအချိန် နောက်ဆုံးလောက်မှ ထားလိုက်တော့ ၂ စက္ကန့်လောက်နဲ့ အဆင်ပြေလာတော့မှ တရားခံအစစ်ကိုမိတယ်။
ပြဿနာအစစ်ကို မိပြီဆိုရင်တော့ ပြင်ဖို့အတွက်က လူအင်အားပဲလိုတယ် Query စာရင်းလိုက်ပေးလိုက် တခုချင်းစမ်းကြည့် Find Query တွေအတွက်ကို explain("executionStats") နဲ့ Execution Plan ကိုကြည့် လိုအပ်တဲ့ Index တွေမရှိတာတွေ့ရင် စာရင်းလုပ်ခိုင်း။ Aggregation တွေကတော့ ပထမအဆင့်အနေနဲ့ options ကို {explain: true} Execution Plan ကိုကြည့် နောက်တဆင့်က Execute လုပ်ကြည့် Optimum ဖြစ်ဖို့အတွက်က Data တွေကို Pipeline အဆင့်ဆင့်အလိုက် နည်းသွားရမယ့် Cost ကြီးတာတွေကို ဖြစ်နိုင်မယ်ဆိုရင် Data နည်းသွားမှလုပ် နောက်ကိုရွှေ့ စသည်ဖြင့်တွေ သတိထားခိုင်းလိုက်ပြီး အင်တိုက်အားတိုက် ပြင်ခိုင်းရတော့တယ်။ တကယ်ကတော့ Optimization ဆိုတာ ခက်တယ်တော့ မဟုတ်ပါဘူး ဘယ် Product သုံးမှ ဆိုတာလည်းမဟုတ်ဘူး ဘယ်လိုအချိန်ဆို နှေးသွားတတ်တယ် သိထားပြီးတော့ သတိထားနေဖို့ပဲလိုပါတယ်။
References
- Introducing mtools - https://www.mongodb.com/blog/post/introducing-mtools
- mtools - https://github.com/rueckstiess/mtools
- python matplotlib framework under macosx - https://stackoverflow.com/questions/4130355/python-matplotlib-framework-under-macosx
- Aggregation Pipeline - https://docs.mongodb.com/manual/core/aggregation-pipeline
- Aggregation Pipeline Optimization - https://docs.mongodb.com/manual/core/aggregation-pipeline-optimization/
- Analyze Query Performance - https://docs.mongodb.com/manual/tutorial/analyze-query-plan/